I remember the software engineering course I took during my last two semesters of study. We learned UML, OOP, project planning, CASE tools, documentation, a bunch of design patterns and lots of other tactics to tame huge hypothetical abstract software codebases. The problem was that, in fact, they remained abstract in my mind.
As students, we never dealt with code longer than some thousands of lines of code. I distinctly remember how proud I was the first time I wrote a C program that was longer than 1000 lines. If you enjoy programming though, chances are that you will get some sort of job involving development. Additionally, you will likely deal with a large legacy codebase.
That’s the old passage to Ravenholm. We don’t go there anymore.
– Alyx Vance, Half Life 2
That’s what all the nice things you learned during your software engineering lectures were for, right? It turns out it’s not that easy to apply that knowledge. For example, at the beginning I had a hard time to understand design patterns in practice. All I had was my GoF book sitting there and judging me from the shelf. I wanted to keep things pragmatical, though, and not overcomplicate things, so I rarely saw where patterns fit the picture. Considering that I was working on a legacy codebase that had no distinguishable patterns whatsoever, it didn’t look like a problem.
Little did I know that the codebase I was working on at the time was very far from the quality standards that the industry strives to achieve. Lacking any form of automated tests, working on the code was painful and many bug fixes felt like hacks. I was even more oblivious to the fact that a lot of projects are in this state nowadays all around the world.
Without a mentor, I turned to the Internet. I gathered a list of books about principles we didn’t treat in our coursework and started avidly reading. So this is the list of books I wish I had 5 years ago, when I was a junior developer working on a huge legacy codebase.
This book I found on Jeff Atwood’s blog, and it was so influential for him that he named his blog after a mechanism used in the book to identify bad practices, highlighted as “coding horrors”. I started reading it during my last year of study, but I went back to it when I started working and found out it’s full of practical tips. Very recommended at the beginning of your career.
This one contains a lot of best practices and is a wake up call for professionalism. It is opinionated, but opinions are what a junior developer needs, especially without mentors around. A must read for everyone in our industry working in object oriented land.
When you know how code is supposed to look like, you want to make your code “cleaner”. These two books show you how to get there starting from a sub-optimal codebase. It is not easy and it requires patience and discipline, but it’s far from impossible. While you are untangling the coupled concepts from the codebase, you will want to test them. That is why the next book is…
This is a very easy read about unit testing and the concepts behind it. It also contains lots of practical advice on how to structure tests and how to get started if all you have is a blank slate. If you feel the need to have a deeper understanding of testing, stubs and mocks you can always dive into xUnit Test Patterns. It’s a bit long, but I found the first part of the book especially useful.
HFDP takes the GoF patterns and puts them into scenarios where you can see how and why they fit. It has been very useful to get some practical insight that was lacking from the GoF book.
Weinberg wrote this a long time ago, but I believe it still contains very relevant advice. When you know how to write better software, you will want to tell your colleagues and convince your boss, and it is possible that you will meet some resistance in the process. This book tells you how to present your ideas and gain traction, whether you want to pursue the management path or not.
What do you think, what books should junior developers read?
I have been asked for advice on how to wade through the masses of information available online to developers. Every day there is something new and everybody wants your time, vendors try to convince you that their products are the best and will live forever then dump a product shortly after (cough cough silverlight cough cough). So how can one make sense of this huge mass of information?
First of all, filter. I can’t stress this enough: a fast-paced industry like ours leads to technologies and frameworks being born and dying almost on a daily basis (I am looking at you, JavaScript frameworks). Following every trend is like drinking from the firehose and would drive anyone crazy over a longer period of time. There are exceptions to this rule, obviously: before knowing what to filter out, you want to find out what you are interested in, so it makes sense to look around occasionally.
Prioritize. When you have a set of technologies and concepts you are interested into, you need to start somewhere. The high priority items on the list are the ones that are being adopted right now by the rest of the industry, if you are lucky, and the ones that have been adopted since forever, if you are working on a hardcore legacy project.
Pace yourself. There is no need to sprint, we’re here for the long run. Choose a comfortable pace at which you can learn and try to stick to it.
Create routines. Make learning part of your daily routine. My news aggregator helps me in giving me my daily dose of what’s happening around the world. As discussed previously, filtering the news you are getting served every day is the only way to remain sane when it comes to your news feeds. Pick a few high quality sources to maintain a high signal-to-noise ratio.
Get involved in the community. Online or offline, conferences or forums, Stackoverflow, nowadays you have lots of possibilities to get in touch with passionate developers. Learn and teach, attend to and give talks, whatever your time allows for, interacting with other developers can be very rewarding. And I know that in Europe we shun it, but Twitter can have its uses.
Everything until now is fine and dandy, but a bit abstract. A way to concretize it is using ThoughtWorks technology radar. The radar allows you to both filter and prioritize technologies and techniques you are interested into, therefore deciding your level of commitment to them.
The implementation might look complicated, but it is really quite simple. You have four categories called Techniques, Tools, Platforms and Language & Frameworks. Each category is subdivided into four layers defining the relevance to the industry of the topics, which go from “hold off for now” to “this technology should be used in modern software development”. The idea is to regularly keep track of what’s on your radar and modify it as you grow, guiding your learning choices. For more details here you can find information on how to build your own technology radar.
If you are staring at an empty news aggregator, here is a selection of some of the sources I have in my feed in no particular order:
ASMX web services have been defined a legacy technology for a while now. In fact, Microsoft itself put a disclaimer on the MSDN documentation page regarding ASMX.
This is not going to be news to the most of us, but we still kept creating services with ASMX. The problem is that I keep seeing projects implementing web services with ASMX instead of WCF. So why are we working with a legacy technology, while Microsoft keeps recommending against it?
Because WCF is a pain. It can do everything, but it always felt clunky for something small and simple like a web service. Have you ever seen the standard configuration of a WCF service, the one that is added by default when you create a service?
It makes me want to poke my eyes out. StrongWildCard? ReaderQuotas? It is a huge amount of unnecessary cryptic information. In fact, it is so bad that in the book “Programming WCF Services” there is an explicit essential coding guideline for configuration files: “Do not use SvcUtil or Visual Studio 2010 to generate a config file”. What about sharing the session with ASP.NET? Yes, it might be frowned upon, but it worked out of the box with ASMX. Oh right, you have to extend the configuration setting the aspNetCompatibilityEnabled attribute to true. As if the configuration weren’t large enough.
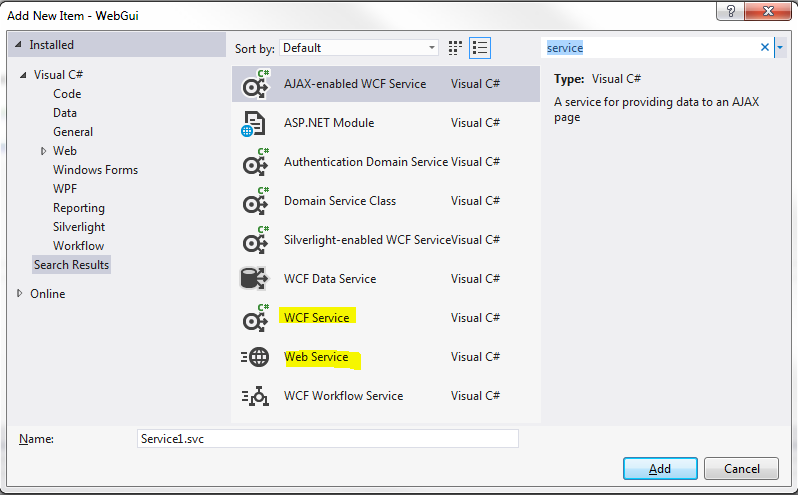
To make the matter worse, we are also deceived when we want to create a new web service. Suppose that we are asked to create a web service to expose a certain functionality of our application, when we go to Visual Studio we are faced with this:
Since we are about to create a web service we should probably choose the “Web Service” item from the list, right? Guess what that is? An ASMX Web Service. So much for legacy technology, this surely does not help the adoption of WCF services.
All in all, it has been difficult to convince developers to use WCF in the last years. Luckily Microsoft noticed, hence things have changed and with .NET 4.5 they simplified things a bit. Enter .NET 4.5 and the WCF “Simplification Features”.
For starters, there is a new default configuration.
Much less intimidating than the older one, isn’t it? And we don’t need to bother to configure the ASP.NET compatibility mode, since it is activated by default now, meaning that we can access ASP.NET session out of the box. There are some other improvements that you should check out on the dedicated page on MSDN.
Cacheable queries are a powerful tool in the belt of the caching-aware developer. They save the results of a query as a collection of identifiers, so that if the same query is executed again we can avoid hitting the database and just return the previously loaded results. Even though this sounds simple, there are two common pitfalls when using it: one concerns performance directly, and the other makes your cache return stale results.
The first pitfall, common to all second level cache implementations, is not to cache the entities that are returned by the query. In fact, when NHibernate finds any cached query results, it goes through the list of identifiers to fetch the entities one by one. However, if the entities themselves are not cached we run into a problem – supposing that we cached the results of a query returning 1000 entities, NHibernate is going to execute 1000 selects.
Concretely, to avoid this problem you must make sure to have configured the entities that will be returned by your query to be cached correctly. In this case it is evident that we are degrading the performance of our system instead of improving it. However, there is a lurking misconfiguration affecting the freshness of the cached data instead of raw performance, which is much more difficult to spot.
I have noticed that developers often avoid to define a cache region for cacheable queries – which is not necessarily an issue, especially when using SysCache. Despite the fact that there is no need to set the region, if you leave it out you should do so consciously. While this configuration works fine for SysCache, this deceivingly small detail has deep repercussions on how the cache is invalidated when using SysCache2.
Although there exists a default cache region containing the cached query results (NHibernate.Cache.StandardQueryCache), if you do not explicitly define a region for a cacheable query you get no automatic invalidation via query notifications. This is due to the fact that the standard query cache region is not configured to support query notifications and it might be an issue if the default relative expiration of 5 minutes of StandardQueryCache has been increased. As a matter of fact, we manually configured some of our cache regions to expire after a time frame of multiple hours, meaning that we were seeing several instances of this problem.
In case you are not familiar with query notifications, think of them as a service that receives a query and notifies you if the result of the query has changed due to changes in the underlying data. You can then keep the program running normally until SQL server sends you a notification, at which point you will want to react and, in case you are caching that data, invalidate your stale cache entry. This is all handled for you in the background by SysCache2 and a number of BCL classes. You might have noticed that in order to check the data for changes, SQL Server needs to know which query has to be monitored. It turns out that the default query cache has no such query defined, which makes sense, considering it is the cache region used for all queries and can’t predict which entities will be involved in it.
In order to solve the staleness issue, you can use a custom cache region configured for query notifications. All things considered, if we are using SysCache2 we probably already defined cache regions containing either command- or table-based dependencies, which we can reuse for invalidating stale query results. More precisely, supposing that you are using QueryOver, your cacheable query will look like this:
Sharing the cache region between queries and entities to be cached also has an additional benefit: suppose that you cached the results of the query in a different region, and your entity cache region is invalidated. The next time you are going to perform the query you are going to incur in the first problem that we met: the resulting ids of the query are still cached, but the entities themselves are not cached anymore. If you used the same cache region for both purposes this is not going to happen.
So as you have seen, caching queries is a way to squeeze some performance out of the system, but if not configured correctly it will backfire badly.
Imagine spending days carefully setting up and fine tuning NHibernate caches, the whole lot of them: session, second level and query cache. Suppose you have spent way too long in finding out how to set up SysCache2 and query notifications in SQL Server, how to create a perfect combination of permissions so that everything works smoothly. After the web app has been deployed to the test system, you receive a call asking you to check the behavior of the second level cache that may be the cause of a timeout.
Mh, sounds weird, but ok. I look into it and everything looks fine at first glance: reading the debugging output from the second level cache, it appears that everything is being cached and fetched from the cache correctly. Until I hit one button and try to reproduce that timeout, succeeding. The cache is being completely cleared and during the next attempt to fetch a cached model entity the cache is rebuilt again from scratch, blocking due to a transaction that was started by the operation itself. What? Why is it happening?
After all the time spent in the caching code, this defies everything I know about the second level cache. The cache region isn’t expiring, it is being explicitly cleared even if there is no such explicit request from our code. A future me will have to admit that yes, we didn’t have an explicit request to clear the cache, but we had something very close to it. A Clear() in disguise.
Stepping through the code I isolate the method call unleashing the total annihilation of the cache: it is a call to ISQLQuery.ExecuteUpdate. And then it dawns on me – we are performing a native update/delete/insert operation on the database and NHibernate has just to assume that we may have changed something that has already been cached. Which means that the second level cache is completely wiped clean in the name of consistency. Ouch.
While it may make sense for NHibernate to keep the caches consistent knowing nothing about their implementation, we are actually using SysCache2 which employs SQL Server’s Query Notification system to be notified about changes in the data, automatically invalidating the related cache item. This is extremely cool – and a huge PITA to setup correctly – but now NHibernate has to ruin our fun and spoil the party. I start looking into options to limit the damage to the cache, supposing that at least it should be possible define some regions to be cleared, or maybe turn off the option completely.
While checking NHibernate sources reveals that there is an half-ported feature of Hibernate called query spaces that could be used to define regions that will be cleared, I wasn’t able to leverage it and I assume it was not fully implemented in NHibernate, though I could be wrong. You can find the relevant code in BulkOperationCleanupAction.
/// <summary>/// Create an action that will evict collection and entity regions based on queryspaces (table names)./// </summary>publicBulkOperationCleanupAction(ISessionImplementorsession,ISet<string>querySpaces){//from H3.2 TODO: cache the autodetected information and pass it in instead.this.session=session;ISet<string>tmpSpaces=newHashSet<string>(querySpaces);ISessionFactoryImplementorfactory=session.Factory;IDictionary<string,IClassMetadata>acmd=factory.GetAllClassMetadata();foreach(KeyValuePair<string,IClassMetadata>entryinacmd){stringentityName=entry.Key;IEntityPersisterpersister=factory.GetEntityPersister(entityName);string[]entitySpaces=persister.QuerySpaces;if(AffectedEntity(querySpaces,entitySpaces)){if(persister.HasCache){affectedEntityNames.Add(persister.EntityName);}ISet<string>roles=session.Factory.GetCollectionRolesByEntityParticipant(persister.EntityName);if(roles!=null){affectedCollectionRoles.UnionWith(roles);}for(inty=0;y<entitySpaces.Length;y++){tmpSpaces.Add(entitySpaces[y]);}}}spaces=newList<string>(tmpSpaces);}privateboolAffectedEntity(ISet<string>querySpaces,string[]entitySpaces){if(querySpaces==null||(querySpaces.Count==0)){returntrue;}for(inti=0;i<entitySpaces.Length;i++){if(querySpaces.Contains(entitySpaces[i])){returntrue;}}returnfalse;}
As you see, it looks like there is a possibility to define query spaces so that the AffectedEntity method can discard only the relevant regions, yet I couldn’t find a public method where to inject the query spaces. So no luck leveraging NHibernate features for me, I would have to solve the issue myself in the less hacky way possible. It turns out that there is a workaround to this issue that is also quite easy to implement.
The solution is simply to remove all the ISQLQuery.ExecuteUpdate calls and execute the relevant statements over ADO.NET, reusing the connection and enlisting the command in the existing transaction. Doing this we effectively perform the update/insert/delete statements behind NHibernate’s back, however we will not need to worry about inconsistencies since SysCache2 is there to save the day. Thank you, SysCache2: the pain of setting up the permissions and double checking that you were working correctly was totally worth it.